はじめに
こんにちは!
askenでMLエンジニアとして働いているyumaです。shoku-pan🍞という名前でTwitterをやってます。
前回は社内Slackの人気絵文字ランキングを調べました。
Slack Appを使ってSlackから絵文字データを抽出して、bar chart raceを使ってランキングをアニメーションで表示することができました。
今回もSlackデータの分析を行います。 askenのSlackコメントを分析して、どういったワードがよく使われているかを調べてみました\\\ ٩( 'ω' )و ////
全体の流れ
まず、全体の流れは以下になります。
Slack Appのインストール
前回同様、Slackからデータを取得するためにSlack Appを作成・インストールします。Slack Appの作成方法は、こちらの記事を参考にしました。
作成後、Slackのワークスペースにインストールできればいよいよ実装です。
実装
今回も言語はPython、環境はGoogle Colaboratoryを使用しました。
Slackからコメント一覧を取得
それではまず、Slackからコメント一覧を取得するために必要な設定をしておきます。
TOKEN = '[token ID]' channels = [ '[channel ID1]', '[channel ID2]', '[channel ID3]', # 対象とするチャンネルを全て指定 ]
コメントの取得にあたっては、[token ID]と[channel ID]が必要になります。
[token ID]には、Slack APIのUser OAuth Tokenを指定します。
[channel ID]の確認方法は以下を参照ください。
今回、以下5つのあすけんSlackチャンネルからデータを収集しました。
| チャンネル名 | 説明 |
|---|---|
| random | 雑談用チャンネル |
| engineer | エンジニア専用チャンネル |
| learning | 日々学んだこと、情報やナレッジを共有するチャンネル |
| cat | 🐈猫民の猫民による猫民のためのチャネル🐈 |
| muscle | 筋肉専用チャンネル |
それでは、Slackからコメント一覧を取得してみましょう。
import pandas as pd import requests import re def get_conversations_history(channel, limit): url = "https://slack.com/api/conversations.history" headers = {"Authorization": "Bearer "+TOKEN} params = { "channel": channel, "limit": limit, } return requests.get(url, headers=headers, params=params) text_list = [] for channel in channels: conversations_history = get_conversations_history(channel, limit=1000) for i in conversations_history.json()['messages']: if 'bot_id' not in i: # botは除く text_list.append(i['text'])
Slackでコメント一覧を取得するためのAPIはconversations.historyです。
get_conversations_history関数で、指定したチャンネルのコメントを取得しています。
なるべく多くのデータを集めたかったので、limit=1000としました。
text_listに取得したデータが入っています。
前処理
次に、前処理としてテキストの整形を行います。
上記で取得した生データを見ると、以下のような文字列が含まれているのがわかります。
12:34:時刻:hoge::絵文字リアクション<http://hogehoge>:URL<@hoge>: メンション$gt;:引用を表す文字列- 空白文字(スペースや改行)
これらは分析の対象外としたいので削除しておきます。
def preprocess_text(text): """テキストから不要な文字を削除""" text = re.sub(r'<http.+>', '', text) # urlの削除 text = re.sub(r'\d{1,2}:\d{1,2}', '', text) # 時刻(12:34など)の情報は削除 text = re.sub(r':.+:', '', text) # リアクション(:smile:など)の削除 text = re.sub(r'<@.+>', '', text) # メンションの削除 text = text.replace('> ', '') # 引用部分の削除 text = re.sub(r'\s', '', text) # 空白文字(スペースや改行)の削除 return text preprocessed_text_list = [preprocess_text(i) for i in text_list] preprocessed_text_list = [i for i in preprocessed_text_list if i != ''] # 空の要素を削除
preprocessed_text_listには、前処理済みのデータが入っています。
一旦テキストファイルに保存しておきましょう。
with open('slack_all_text.txt', mode='w') as f: f.write('\n'.join(preprocessed_text_list))
形態素解析
さて、分析するデータが準備できたので、次は形態素解析を行います。 今回は形態素解析器としてMeCab、辞書は新語や固有表現に強いmecab-ipadic-NEologdを使用します。
まずはMeCabや辞書をインストールします。
(インストールにはちょっと時間がかかります)
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1 !pip install mecab-python3 > /dev/null !ln -s /etc/mecabrc /usr/local/etc/mecabrc !echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
それでは形態素解析を行います。
形態素解析の結果、各単語に分かち書きされて品詞が付与されます。
今回は、重要な情報の多くは名詞が担っているはずだと考え、名詞のみを抽出対象にしました。
import MeCab path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd" tagger = MeCab.Tagger(path) def morphological_analysis(text): """形態素解析して結果をリストを返却""" node = tagger.parseToNode(text) result_list = [] # pos_list = ['名詞', '動詞', '形容詞'] # 対象とする品詞を指定 pos_list = ['名詞'] # 今回は名詞のみ対象 while node: surface = node.surface feature = node.feature pos = feature.split(',')[0] if surface and pos in pos_list: result_list.append(surface) node = node.next return result_list word_list = [] # すべての単語リスト(1次元リスト) word_list_by_sentence = [] # 文ごとの単語リストのリスト(2次元リスト) for text in preprocessed_text_list: result_list = morphological_analysis(text) word_list += result_list word_list_by_sentence.append(result_list)
word_listは名詞のリスト(1次元リスト)、word_list_by_sentenceはセンテンス(文)ごとの名詞のリストのリスト(2次元リスト)となっています。
WordCloud
ここまでで、Slackのコメントで使われている大量の名詞データが手に入りました。ここからがいよいよ分析です!
まず、どういったワードがよく使われているかを調べるため、WordCloudを使ってみます。WordCloudとは、文章中で出現頻度が高い単語ほど大きく表示する図法のことです。
WordCloudで日本語を表示するために必要なフォントをあらかじめインストールしておきましょう。
!wget https://noto-website-2.storage.googleapis.com/pkgs/NotoSansCJKjp-hinted.zip
!unzip NotoSansCJKjp-hinted.zip
それでは、WordCloudを描いてみます。
import matplotlib.pyplot as plt from wordcloud import WordCloud def plot_wordcloud(text, max_font_size=200, min_font_size=10, background_color='black'): """単語ごとにスペースで区切られたテキストを入力として、wordcloudを表示する""" wordcloud = WordCloud( font_path='NotoSansCJKjp-Black.otf', width=900, height=700, background_color=background_color, max_font_size=max_font_size, min_font_size=min_font_size, collocations = True, ).generate(text) plt.figure(figsize=(15,12)) plt.axis("off") plt.imshow(wordcloud) plt.savefig("word_cloud.png") plt.show() text = ' '.join(word_list) plot_wordcloud(text, max_font_size=200, min_font_size=10, background_color='black')

うまく表示することができました!
頻出のワードほど大きく表示されています。
ここで、パッと見でもわかるように、「こと」「そう」「ため」などといった情報を持たないワードが大きく出てしまっています。
こういった、一般的すぎるが頻出するワードのことを「ストップワード」といい、処理の対象から除外するのが一般的です。
ストップワードを削除した結果は以下になります。

先程まで目立たなかった「お願い」「今日」「アプリ」といったワードが全面に出てきましたね!
「お願い」は「よろしくお願いします」という形で非常に多く使われています。 また、「今日」は「今日もよろしくお願いします。」「今日の〜」といったコメントが多いために大きく表示されているようです。 「アプリ」は、弊社askenのダイエットアプリあすけんやその他アプリについて言及されることが多く、頻出ワードとなっています。
さて、ストップワードの除去には、
- 辞書による方式
- 出現頻度による方式
の大きく2つがあり、今回は辞書による方式を採用しました。
一方、出現頻度による方式とは、単語の頻度をカウントして頻度の高いもの(場合によっては低いもの)を除外する方法です。高頻度の単語は、全体に占める割合が大きいにもかかわらず、重要な情報を持っていないことが多いという考えに基づいています。
さらに、単語の出現頻度(term frequency:単語の出現頻度)をそのまま用いるのではなく、それに単語が出現する文書数の逆数
(inverse document frequency:逆文書頻度)をかけて考えるtf-idfという方法があります。
ここで、
は文書
における単語
の出現頻度、
は単語
が出現する文書数、
は全文書数です。
tf-idfでは、多くの文書に出現する語の重要度を下げ、逆に特定の文書にしか出現しない単語の重要度を上げることができます。
その結果、各文章に特徴的な単語を抽出することができ、ある程度ストップワードも取り除くことができると考えられます。
今回、tf-idfは使用しませんでしたが、気になる方はこちらのたかぱいさんの記事が大変わかりやすいのでご覧ください。
N-gram
さて、WordCloudを描いて頻出のワードを調べてみました。
これは、ワード単体1で見るのには大変便利で、見た目のインパクトもあって大変面白い方法です。
では次に、どういった組み合わせで単語がよく使われているかを調べるため、N-gramを使ってみましょう。
N-gramを用いると、連続して使われる単語(あるいは文字)を調べることができます。
from collections import defaultdict import plotly.graph_objects as go def n_gram(word_list_1d, n): """ngramのリストを返す""" ngram_list = [] for i in range(len(word_list_1d)-n+1): ngram_list.append(' '.join(word_list_1d[i: i+n])) return ngram_list def show_bar_plot(df, color): """棒グラフを表示する""" fig = go.Figure(go.Bar( x=df["wordcount"].values[::-1], #少ない順に並んでしまうので逆順にする y=df["word"].values[::-1], # xと同様 showlegend=False, orientation = 'h', marker=dict( color=color, ), )) fig.update_layout( margin=dict(l=100, r=20, t=20, b=20), paper_bgcolor="LightSteelBlue", height = 200, width = 1000 ) fig.show() def show_ngram_bar_plot(word_list_2d, n, top_n=30, color='blue'): """ngramの結果を棒グラフで表示する""" freq_dict = defaultdict(int) for word_list_1d in word_list_2d: for ngram in n_gram(word_list_1d, n): freq_dict[ngram] += 1 df = pd.DataFrame.from_dict(freq_dict, orient='index') df.sort_values(0, ascending=False, inplace=True) df = df.reset_index().set_axis(['word', 'wordcount'], axis='columns') show_bar_plot(df[:top_n], color=color) # unigram show_ngram_bar_plot(word_list_by_sentence, n=1, top_n=10, color='blue') # bigram show_ngram_bar_plot(word_list_by_sentence, n=2, top_n=10, color='green') # trigram show_ngram_bar_plot(word_list_by_sentence, n=3, top_n=10, color='red')
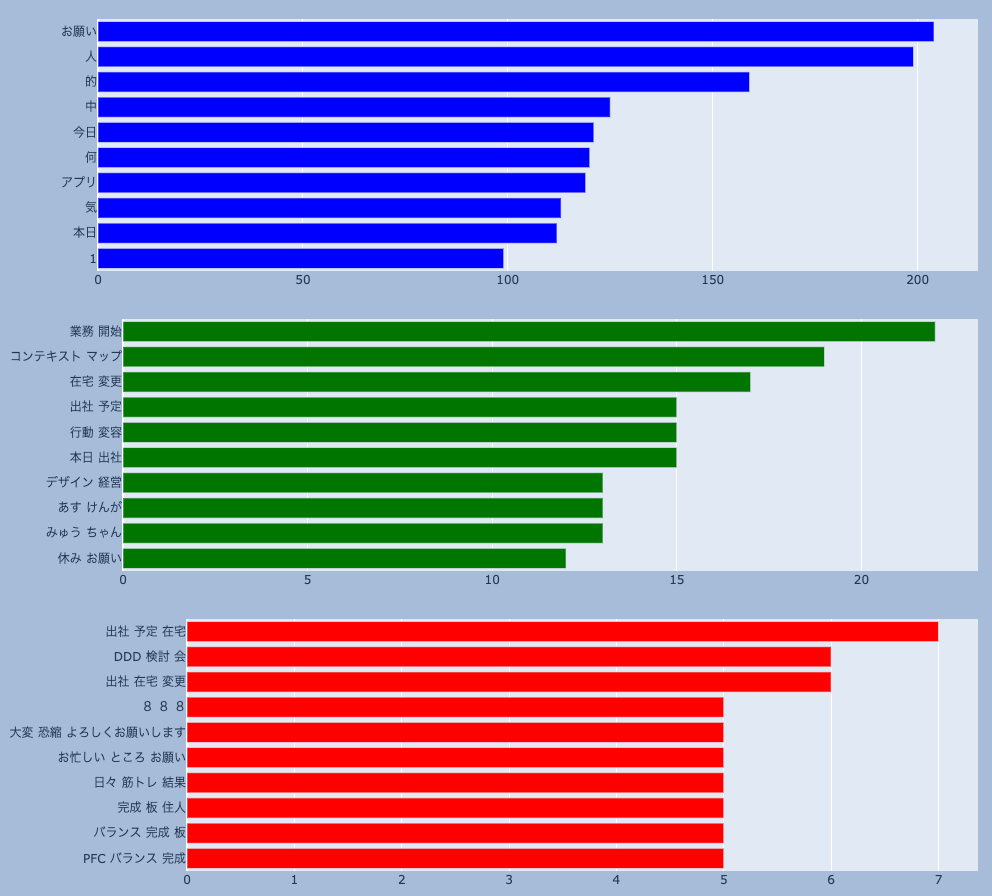
unigram(N=1)、bigram(N=2)、trigram(N=3)のトップ10を棒グラフで出してみました。
unigramはWordCloud同様、単体で使われるワードを多い順に並べたものになっています。
bigramには、「業務/開始」「コンテキスト/マップ」「在宅/変更」といった単語の組み合わせがランクインしています。これは、勤怠の連絡やDDD(ドメイン駆動設計)の勉強の話が多くされていることを表しています。askenではDDDをはじめ、多岐にわたるテーマの勉強会が活発に行われており、Slackでもよく意見が交わされているようですね。
ところで「みゅう/ちゃん」とは、社員が飼っている猫の名前です。askenには猫好きな社員が多く(犬好きもいます)、オンライン会議ではお目見えすることもあります![]()
trigramには「筋トレ」というワードが入っています。仕事柄健康に対する意識の高さから、食だけではなく運動も強く意識する社員が多いですね。最近ではランニングや登山といった話題が人気のようです。
Sentencepiece
ここまで、WordCloudおよびN-gramを使って、頻出ワードを調べてみました。
ところで、これらはいずれも辞書を用いた分析であり、実は辞書に登録されていない単語(未知語)にはうまく対応できません。たとえば、bigramの結果をあらためてよく見ると「あす/けんが」とあります。これは、使用した辞書(NEologd)に「あすけん」という単語が登録されていない未知語のためです(早く登録してもらえるように頑張ります…)
そこで、辞書に頼るのではなく、データを学習してより未知語にも対応できるようにすることを考えます。そこで登場するのがSentencepieceという手法です。
Sentencepieceとは、ざっくりと言うと、従来の「文法的に正しい分割」ではなく、学習データである生のテキストから最適な分割点を学習しようというものです。
詳細は、しんちろさんのこちらの記事がすごくわかりやすいので参考になさってください。
Sentencepieceを使うために、インストールしておきましょう。
!pip install sentencepiece
また、Sentencepieceと辞書ベースのMeCabの分かち書きを比較するための関数も用意しておきます。
import sentencepiece as spm def tokenize_mecab(text): node = tagger.parseToNode(text) result_list = [] while node: surface = node.surface if surface: result_list.append(surface) node = node.next return result_list # しんちろさんのコードを参考にしました def tokenize_sp(input_text: str, model_path: str) -> list: '''SentencePieceによる分かち書き''' # モデルの読み込み sp = spm.SentencePieceProcessor() sp.Load(model_path) # sentencepieceによる分かち書き tokenize_list = sp.EncodeAsPieces(input_text) # 必ず最初に'▁'が入るため削除 tokenize_list = [token.replace( '▁', '') for token in tokenize_list if token.replace('▁', '') != ""] return tokenize_list
それではSentencepieceを使って学習を行いましょう。
保存しておいた前処理済みのテキストデータのファイルを読み込みます。
spm.SentencePieceTrainer.Train(
input='slack_all_text.txt',
model_prefix='sentencepiece',
vocab_size=2000,
character_coverage=0.9995
)
学習が終わったら分かち書きしてみましょう。
MeCabの結果と比較すると以下のようになりました。
text = 'あすけんはダイエットアプリです。' print(tokenize_mecab(text)) # Mecab print(tokenize_sp(input_text=text, model_path="sentencepiece.model")) # sentence piece # ['あ', 'すけん', 'は', 'ダイエットアプリ', 'です', '。'] # ['あすけん', 'は', 'ダ', 'イ', 'エ', 'ット', 'ア', 'プ', 'リ', 'です', '。']
MeCabでは「あ/すけん」と分かれてしまっていますが、Sentencepieceでは「あすけん」と正しくわけられていますね! 「あすけん」というワードが多くの文章に登場しており、分割点をうまく見つけられたようです。
一方で、「ダイエットアプリ」というワードに関しては、細かく分かれすぎていてMeCabが勝った形となりました。 Sentencepieceの学習に関しては、「あすけん」というワードは十分な数あるが、「ダイエットアプリ」というワードは十分ではなかった、と考えられます。
単語の分散表現
ここまでで、MeCabを使った辞書ベースの分析、Sentencepieceによる学習と分析をやってきました。
次に、単語の分散表現について見てみようと思います。 分散表現(あるいは単語埋め込み、word embedding)とは、単語を高次元の実数ベクトルで表現する技術です。分散表現を得るために、Word2Vecを使用します。
Word2Vecを使用するために、gensimをインストールしておきます。
!pip install gensim
インストールできたら、Word2Vecのモデルを作成してみましょう。
センテンスごとに分けた単語のリストword_list_by_sentenceに対して学習を行います。
from gensim.models import word2vec model = word2vec.Word2Vec(word_list_by_sentence, size=300, min_count=5, window=5, iter=100) model.wv.save_word2vec_format('word2vec.bin', binary=True) # モデルの保存
学習が終わったら、単語の分散表現を確認してみましょう。
例として、「ダイエット」という単語を見てみます。
print(model.__dict__['wv']['ダイエット']) # [ 0.52999353 -0.23631863 -0.00984514 -1.1539422 0.65169364 -0.33282238 # -0.8465534 -0.06162367 2.0389488 -0.03625611 0.54652476 -0.83955187 # -0.6747863 -0.5368701 -0.2588077 1.1441534 -0.25403473 0.22454463 # 0.10980017 0.90397495 1.97433 -1.2201335 -0.85706323 -0.06221941 # 1.7707006 0.39611042 -0.66982204 0.0743041 -0.33158022 -1.0384009 # (以下略)
上記では省略していますが、300次元のベクトルになっていることが確認できました。
さて、ベクトル間では類似度を計算することができます。
たとえば、2つのベクトルのコサイン類似度は以下になります。
コサイン類似度は、1に近いほど類似度が高く、-1に近いほど類似度が低いことを表します。
さて、例として「沼」という単語に近い単語トップ10を出してみました。
model.wv.most_similar(positive=['沼']) # [('マグマ', 0.774527370929718), # ('マッスルグリル', 0.732177734375), # ('ツイート', 0.7176527380943298), # ('やってみよう', 0.6925275921821594), # ('ww', 0.6841464042663574), # ('シャイニー', 0.6801939010620117), # ('オートミール', 0.6785858869552612), # ('素人', 0.667254626750946), # ('セメント', 0.6630067825317383), # ('減量', 0.6545518636703491)]
急に「沼」というワードを出してしまいましたが、これはれっきとした料理の名前です。
マッスルグリルのシャイニー薊さんが考案した究極の減量食で、炊飯器さえあれば簡単につくることができ、界隈では大変話題になっています。
「沼」についてはこちらの動画で紹介されています。
結果を見てみると、「マッスルグリル」や「シャイニー」、「減量」といった単語がランクインしており、うまくベクトル化できているようです。 ちなみに、「マグマ」や「セメント」もシャイニーさん考案の料理です。
なお、あすけんでは「沼」「マグマ」「セメント」もメニュー登録されていますw
ぜひアプリで検索してみてくださいね![]()
単語の分散表現の可視化
それでは最後に、上記の分散表現を可視化してみましょう。
といっても、300次元の単語ベクトルをそのまま扱うことはできないので、今回はPCA(主成分分析)で次元削減し、3次元にプロットしてみます。
可視化にあたっては、TensorBoardを使用するのでインストールしておきます。
!pip install torch tensorboardX tensorflow
さらに、さきほど作成したモデルを読み込んで、単語ベクトルの情報をファイルに出力します。
import gensim import torch from tensorboardX import SummaryWriter writer = SummaryWriter() model = gensim.models.KeyedVectors.load_word2vec_format("word2vec.bin", binary=True) weights = model.vectors labels = model.index2word writer.add_embedding(torch.FloatTensor(weights), metadata=labels)
metadata(各単語)とvector(各単語の分散表現)の2つのtsvファイルが作成されますので、これらをTensorBoardを使って描画してみます。
※こちらにファイルをアップロードすることでも表示できます。
%load_ext tensorboard %tensorboard --logdir runs
単語ベクトルが3次元空間にうまくプロットできていますね。
「出社」「DDD」「タンパク質」「沼」「ネコ」という単語に類似する単語トップ10もあわせて表示してみました。
それぞれ、3次元空間上でもある程度まとまっていることが確認できます。
たとえば「タンパク質」を見てみると、「プロテイン」や「ホエイ」「ソイ」そして「牛乳」といったワードが周辺に分布しています。
これらの単語は組み合わせて使われることが多く、そのため特徴量をうまく抽出できているのではないかと考えました!
まとめ
いかがでしたか?
今回は、弊社askenのSlackコメントを分析してみました。
今回の内容をまとめると、以下のようになります。
- Slack APIを使って、Slack内のデータを収集することができる
- MeCabを使うことで辞書ベースの分析ができる
- WordCloudを使うことで、頻出のワードを大きく表示してインパクトのある図を描くことができる
- N-gramを使うことで、どういった組み合わせで単語が使われているかを知ることができる
- 辞書に登録されていない未知語をデータからうまく抽出するために、Sentencepieceという手法がある
- Word2Vecを使用することで、単語の分散表現が得られる
- 分散表現は、類似度を計算したり、次元削減したものを3次元(あるいは2次元)にプロットしたりできる
ぜひ、皆さんも会社のSlackコメントを分析してみてくださいね![]()
お知らせ
askenでは、一緒に働いてくれるエンジニアを募集しています!
www.wantedly.com
主な参考資料
- TF-IDFで見る評価の高いラーメン屋の口コミ傾向(自然言語処理, TF-IDF, Mecab, wordcloud, 形態素解析、分かち書き)
- 自分のTweetを使ってSentencepieceとMeCabの分かち書きの比較を行う
- 機械学習・深層学習による自然言語処理入門
-
正確には、
WordCloudのオプションでcollocations = Trueとしているので、bigramまで表示できています。Falseとすれば単語単体で表示することができます。 ↩